設計思想(アルゴリズム解説)
このページでは、AIが何を見て予測しているか、どの順で評価して印を出しているかを公開します。
予測で見る主な要素
予測では、次の情報を重みづけして総合評価します(レースにより取得できない項目あり)。
- 直近走の着順・着差・内容(まず直近パフォーマンスを重視)
- 過去数走の安定度(好走/凡走の振れ幅)
- 上がり性能と末脚の持続力
- 脚質(逃げ・先行・差し・追込)と想定展開の一致度
- 距離適性(今回距離とベスト距離の近さ)
- 馬場適性(良/稍重/重/不良)
- コース適性(右左回り・直線長・コーナー数)
- レースペース適性(ハイ/ミドル/スロー)
- 通過順の再現性(位置取りの安定)
- 斤量と前走からの増減
- 枠順・馬番の有利不利
- 騎手の近走成績と当該条件での成績
- 騎手と馬のコンビ実績
- 厩舎傾向と輸送負荷
- クラス昇降(相手強化/緩和)の影響
- 休養明け・連戦の状態変化
- 季節・開催時期との相性
- 競馬場ごとのローカル傾向
- 人気・オッズの歪み(過小/過大評価)
- 同レース内の相対比較(メンバー構成差)
etc...(上記に加え、データ整備時に生成する派生特徴を多数利用)
AIレベルの評価
学習ログの実績は 3着予想 ROC-AUC=0.8770、1着予想 ROC-AUC=0.9065 です。
下表の基準では、3着予想は ★4(非常に優秀)、1着予想は ★5(驚異的精度)に相当します。
| レベル | ROC-AUC範囲 | 評価 | 競馬予測における実用性 |
|---|---|---|---|
| ★5 | 0.90 〜 1.00 | 驚異的精度 | 最高精度。的中率は極めて高い想定。条件やデータ品質により変動しうる。 |
| ★4 | 0.80 〜 0.89 | 非常に優秀 | 高精度。的中率は高い水準を期待できるが、万能ではない。 |
| ★3 | 0.70 〜 0.79 | 実用水準 | 一定の再現性。的中傾向は読み取れるが、ブレも残る。 |
| ★2 | 0.60 〜 0.69 | 参考域 | 粗い傾向のみ。的中率への期待は控えめに見るのが妥当。 |
| ★1 | 0.50 〜 0.59 | ランダム近傍 | 実用は難しい。的中は偶然に近い。 |
補足: ROC-AUC は「高いほど順位づけ能力が高い」指標です。0.5 がランダム、1.0 が理論上の完全識別を意味します。
モデルの具体的な考え方
1) データ整形とリーク防止
学習前に、目的変数へ直結する未来情報を除外し、時系列順の整合を厳密に保った特徴量テーブルを作成します。数値特徴の欠損は原則 NaN のままとし、LightGBM の木分割で扱います(カテゴリはダミー化)。
2) 特徴量生成(単体 + 相互作用)
単体特徴(距離、馬場、斤量、騎手成績など)に加え、交互作用特徴(例: 距離×脚質、馬場×枠、斤量変化×休養日数)を設計し、非線形な寄与を表現します。カテゴリ値は木モデルが分割しやすい形へ符号化します。
3) LightGBM(LambdaRank)による学習
同一レース内の出走馬を1クエリとみなし、着順から作った関連度ラベルに対して LambdaRank(listwise)で順位付けを学習します。勾配ブースティング木を弱学習器に用い、木の深さ・学習率・葉の最小サンプル数などで汎化を調整します。
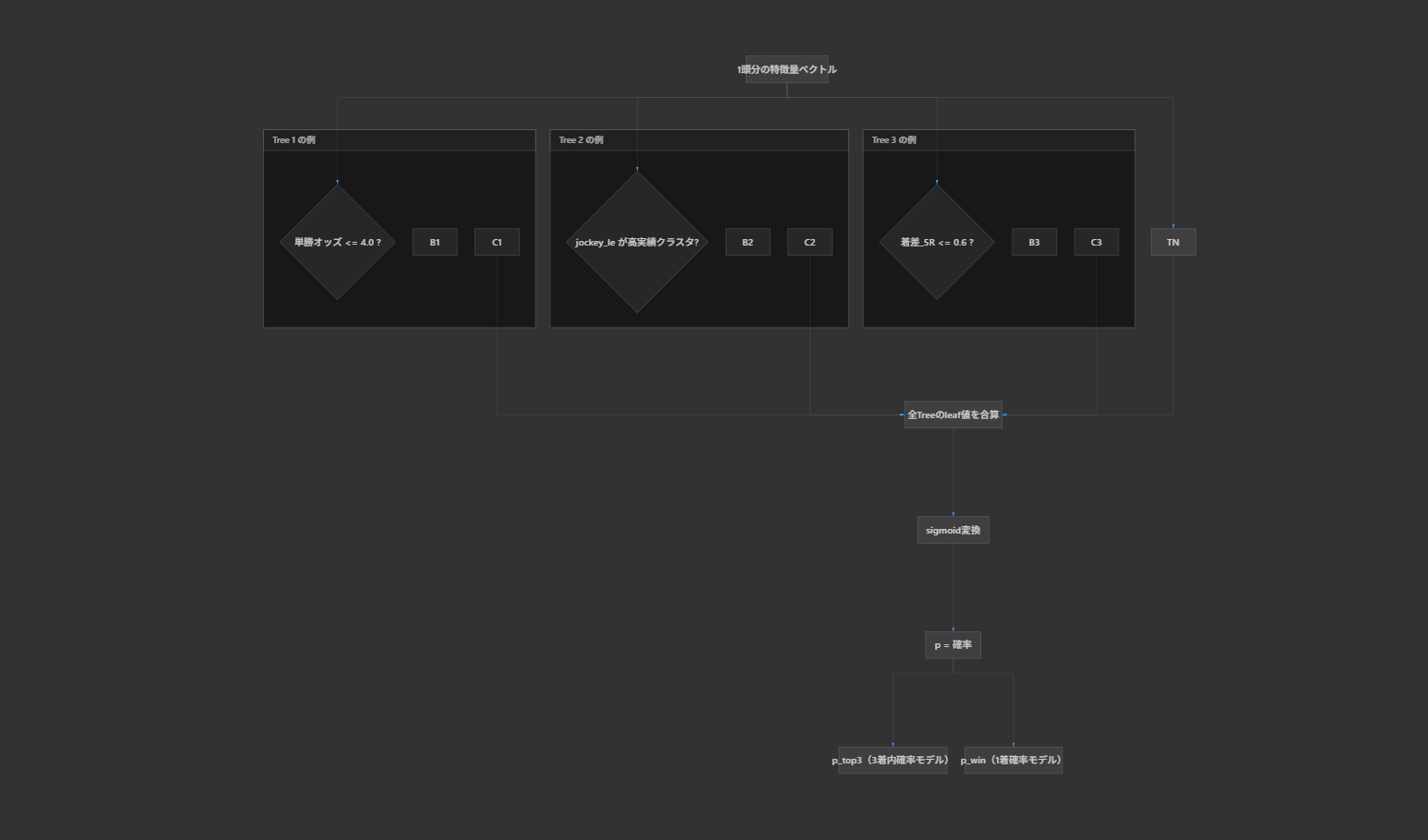
4) スコア校正とレース内正規化
モデルの出力スコアはそのまま使わず、検証データで校正した後にレース内で正規化します。これにより、開催日をまたいだスコアのスケール差を抑え、同一レース内で比較可能な順位尺度へ変換します。
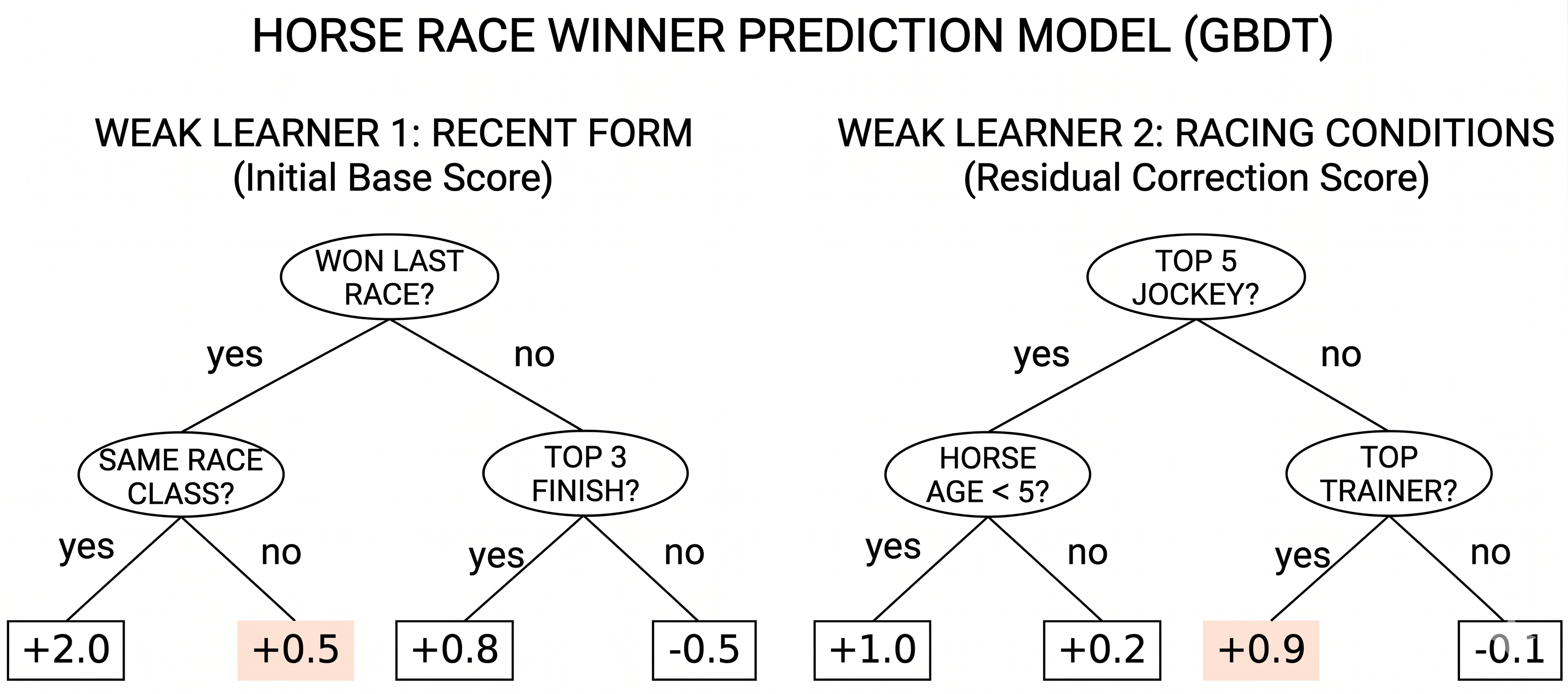
5) 最終意思決定レイヤ
最終段では、予測スコア・推定確率・オッズ情報を統合し、期待値と安定性のバランスで印(◎◯▲)を決定します。UIにはスコアの根拠が追える形で可視化し、ブラックボックス化を抑えています。